

- Introduction to React
- Overview of the Sample Application
- From React Elements to Fiber nodes
- Current and work in progress trees
- Side-effects
- Effects list
- Root of the fiber tree
- Fiber node structure
- Fiber Node Structure
- General algorithm
- Render phase
- Commit phase
- Pre-mutation lifecycle methods
- DOM updates
- Post-mutation lifecycle methods
Introduction to React
React is a JavaScript library for building user interfaces. At its core lies a mechanism that tracks changes in a component state and projects the updated state to the screen. In React we know this process as reconciliation. We call the setState method and the framework checks if the state or props have changed and re-renders a component on UI.
React’s docs provide a good high-level overview of the mechanism: the role of React elements, lifecycle methods and the render method, and the diffing algorithm applied to a component’s children. The tree of immutable React elements returned from the render method is commonly known as the “virtual DOM”. That term helped explain React to people early on, but it also caused confusion and isn’t used in the React documentation anymore. In this article I’ll stick to calling it a tree of React elements.
Besides the tree of React elements, the framework has always had a tree of internal instances (components, DOM nodes etc.) used to keep the state. Starting from version 16, React rolled out a new implementation of that internal instances tree and the algorithm that manages it code-named Fiber. To learn about the advantages which the Fiber architecture brings check out The how and why on React’s usage of linked list in Fiber.
This article would take me a lot longer to write and would be less comprehensive without the help of Dan Abramov! 👍
In this article I want to provide an in-depth overview of important concepts and data structures relevant to the algorithm. Once we have enough background, we’ll explore the algorithm and main functions used to traverse and process the fiber tree.
Overview of the Sample Application
Here’s a simple application that I’ll use. We have a button that simply increments a number rendered on the screen:

And here’s the implementation:
class ClickCounter extends React.Component {
constructor(props) {
super(props);
this.state = {count: 0};
this.handleClick = this.handleClick.bind(this);
}
handleClick() {
this.setState((state) => {
return {count: state.count + 1};
});
}
render() {
return [
<button key="1" onClick={this.handleClick}>Update counter</button>,
<span key="2">{this.state.count}</span>
]
}
}You can play with it here. As you can see, it’s a simple component that returns two child elements button and span from the render method. As soon as you click on the button, the state of the component is updated inside the handler. This, in turn, results in the text update for the span element.
There are various activities React performs during reconciliation. For example, here are the high-level operations React performs during the first render and after state update in our simple application:
- updates
countproperty in thestateofClickCounter - retrieves and compares children of
ClickCounterand their props - updates props for the
spanelement
There are other activities performed during reconciliation like calling lifecycle methods or updating refs. All these activities are collectively referred to as “work” in the Fiber architecture. The type of work usually depends on the type of React element. For example, for a class component, React needs to create an instance, while it doesn’t do that for a functional component. As you know, we have many kinds of elements in React, e.g. class and functional components, host components (DOM nodes), portals etc. The type of React element is defined by the first parameter to the createElementfunction. This function is generally used in the render method to create an element.
Before we begin our exploration of the activities and the main fiber algorithm, let’s first get ourselves familiar with the data structures used internally by React.
From React Elements to Fiber nodes
Every component in React has a UI representation we can call a view or a template that’s returned from the render method. Here’s the template for our ClickCounter component:
<button key="1" onClick={this.onClick}>Update counter</button>
<span key="2">{this.state.count}</span>React Elements
Once a template goes through the JSX compiler, you end up with a bunch of React elements. This is what’s really returned from the render method of React components, not HTML. Since we’re not required to use JSX, the render method for our ClickCounter component could be re-written like this:
class ClickCounter {
...
render() {
return [
React.createElement(
'button',
{
key: '1',
onClick: this.onClick
},
'Update counter'
),
React.createElement(
'span',
{
key: '2'
},
this.state.count
)
]
}
}The calls to React.createElement in the rendermethod will create two data structures like this:
[
{
$$typeof: Symbol(react.element),
type: 'button',
key: "1",
props: {
children: 'Update counter',
onClick: () => { ... }
}
},
{
$$typeof: Symbol(react.element),
type: 'span',
key: "2",
props: {
children: 0
}
}
]You can see that React adds the property $$typeof to these objects to uniquely identify them as React elements. Then we have properties type, key and props that describe the element. The values are taken from what you pass to the React.createElement function. Notice how React represents text content as children of the span and button nodes. And how the click handler is part of the button element props. There are other fields on React elements like the ref field that are beyond the scope of this article.
The React element for ClickCounter doesn’t have any props or a key:
{
$$typeof: Symbol(react.element),
key: null,
props: {},
ref: null,
type: ClickCounter
}Fiber nodes
During reconciliation data from every React element returned from the render method is merged into the tree of fiber nodes. Every React element has a corresponding fiber node. Unlike React elements, fibers aren’t re-created on every render. These are mutable data structures that hold components state and DOM.
We discussed earlier that depending on the type of a React element the framework needs to perform different activities. In our sample application, for the class components ClickCounter it calls lifecycle methods and the rendermethod, whereas for the span host component (DOM node) it performs DOM mutation. So each React element is converted into a Fiber node of corresponding type that describes the work that needs to be done.
You can think of a fiber as a data structure that represents some work to do or, in other words, a unit of work. Fiber’s architecture also provides a convenient way to track, schedule, pause and abort the work.
When a React element is converted into a fiber node for the first time, React uses the data from the element to create a fiber in the createFiberFromTypeAndProps function. In the consequent updates React reuses the fiber node and just updates the necessary properties using data from a corresponding React element. React may also need to move the node in the hierarchy based on the key prop or delete it if the corresponding React element is no longer returned from the render method.
Check out the ChildReconciler function to see the list of all activities and corresponding functions React performs for existing fiber nodes.
Because React creates a fiber for each React element and since we have a tree of those elements, we’re going to have a tree of fiber nodes. In the case of our sample application it looks like this:
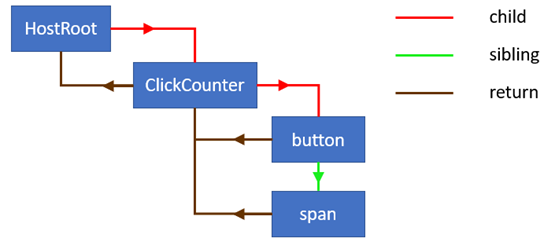
All fiber nodes are connected through a linked list using the following properties on fiber nodes: child, sibling and return. For more details on why it works this way, check out my article The how and why on React’s usage of linked list in Fiber if you haven’t read it already.
Current and work in progress trees
After the first render, React ends up with a fiber tree that reflects the state of the application that was used to render the UI. This tree is often referred to as current. When React starts working on updates it builds a so-called workInProgress tree that reflects the future state to be flushed to the screen.
All work is performed on fibers from the workInProgress tree. As React goes through the current tree, for each existing fiber node it creates an alternate node that constitutes the workInProgress tree. This node is created using the data from React elements returned by the render method. Once the updates are processed and all related work is completed, React will have an alternate tree ready to be flushed to the screen. Once this workInProgress tree is rendered on the screen, it becomes the current tree.
One of React’s core principles is consistency. React always updates the DOM in one go — it doesn’t show partial results. The workInProgress tree serves as a “draft” that’s not visible to the user, so that React can process all components first, and then flush their changes to the screen.
In the sources you’ll see a lot of functions that take fiber nodes from both the current and workInProgress trees. Here’s the signature of one such function:
function updateHostComponent(current, workInProgress, renderExpirationTime) {...}
Each fiber node holds a reference to its counterpart from the other tree in the alternate field. A node from the current tree points to the node from the workInProgress tree and vice versa.
Side-effects
We can think of a component in React as a function that uses the state and props to compute the UI representation. Every other activity like mutating the DOM or calling lifecycle methods should be considered a side-effect or, simply, an effect. Effects are also mentioned in the docs:
You’ve likely performed data fetching, subscriptions, or manually changing the DOM from React components before. We call these operations “side effects” (or “effects” for short) because they can affect other components and can’t be done during rendering.
You can see how most state and props updates will lead to side-effects. And since applying effects is a type of work, a fiber node is a convenient mechanism to track effects in addition to updates. Each fiber node can have effects associated with it. They are encoded in the effectTag field.
So effects in Fiber basically define the work that needs to be done for instances after updates have been processed. For host components (DOM elements) the work consists of adding, updating or removing elements. For class components React may need to update refs and call the componentDidMount and componentDidUpdate lifecycle methods. There are also other effects corresponding to other types of fibers.
Effects list
React processes updates very quickly and to achieve that level of performance it employs a few interesting techniques. One of them is building a linear list of fiber nodes with effects for quick iteration. Iterating the linear list is much faster than a tree, and there’s no need to spend time on nodes without side-effects.
The goal of this list is to mark nodes that have DOM updates or other effects associated with them. This list is a subset of the finishedWork tree and is linked using the nextEffect property instead of the child property used in the current and workInProgress trees.
Dan Abramov offered an analogy for an effects list. He likes to think of it as a Christmas tree, with “Christmas lights” binding all effectful nodes together. To visualize this, let’s imagine the following tree of fiber nodes where the highlighted nodes have some work to do. For example, our update caused c2to be inserted into the DOM, d2 and c1 to change attributes, and b2 to fire a lifecycle method. The effect list will link them together so React can skip other nodes later:
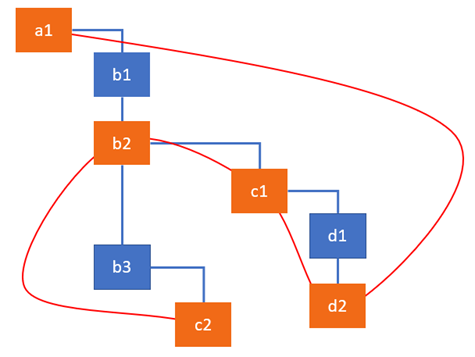
You can see how the nodes with effects are linked together. When going over the nodes, React uses the firstEffect pointer to figure out where the list starts. So the diagram above can be represented as a linear list like this:

As you can see, React applies effects in the order from children and up to parents.
Root of the fiber tree
Every React application has one or more DOM elements that act as containers. In our case it’s the div element with the ID container.
const domContainer = document.querySelector('#container');
ReactDOM.render(React.createElement(ClickCounter), domContainer);React creates a fiber root object for each of those containers. You can access it using the reference to the DOM element:
const fiberRoot = query('#container')._reactRootContainer._internalRoot
This fiber root is where React holds the reference to a fiber tree. It is stored in the current property of the fiber root:
const hostRootFiberNode = fiberRoot.current
The fiber tree starts with a special type of fiber node which is HostRoot. It’s created internally and acts as a parent for your topmost component. There’s a link from the HostRoot fiber node back to the FiberRoot through the stateNode property:
fiberRoot.current.stateNode === fiberRoot; // true
You can explore the fiber tree by accessing the topmost HostRoot fiber node through the fiber root. Or you can get an individual fiber node from a component instance like this:
compInstance._reactInternalFiber
Fiber node structure
Let’s now take a look at the structure of fiber nodes created for the ClickCounter component
{
stateNode: new ClickCounter,
type: ClickCounter,
alternate: null,
key: null,
updateQueue: null,
memoizedState: {count: 0},
pendingProps: {},
memoizedProps: {},
tag: 1,
effectTag: 0,
nextEffect: null
}and the span DOM element:
{
stateNode: new HTMLSpanElement,
type: "span",
alternate: null,
key: "2",
updateQueue: null,
memoizedState: null,
pendingProps: {children: 0},
memoizedProps: {children: 0},
tag: 5,
effectTag: 0,
nextEffect: null
}There’s quite a lot of fields on fiber nodes. I’ve described the purpose of the fields alternate, effectTag and nextEffect in previous sections. Let’s now see why we need others.
stateNode
Holds the reference to the class instance of a component, a DOM node or other React element type associated with the fiber node. In general, we can say that this property is used to hold the local state associated with a fiber.
type
Defines the function or class associated with this fiber. For class components, it points to the constructor function and for DOM elements it specifies the HTML tag. I use this field quite often to understand what element a fiber node is related to.
tag
Defines the type of the fiber. It’s used in the reconciliation algorithm to determine what work needs to be done. As mentioned earlier, the work varies depending on the type of React element. The function createFiberFromTypeAndProps maps a React element to the corresponding fiber node type. In our application, the property tag for the ClickCountercomponent is 1 which denotes a ClassComponent and for the span element it’s 5 denoting a HostComponent.
updateQueue
A queue of state updates, callbacks and DOM updates.
memoizedState
State of the fiber that was used to create the output. When processing updates it reflects the state that’s currently rendered on the screen.
memoizedProps
Props of the fiber that were used to create the output during the previous render.
pendingProps
Props that have been updated from new data in React elements and need to be applied to child components or DOM elements.
key
Unique identifier with a group of children to help React figure out which items have changed, have been added or removed from the list. It’s related to the “lists and keys” functionality of React described here.
Fiber Node Structure
You can find the complete structure of a fiber node here. I’ve omitted a bunch of fields in the explanation above. Particularly, I skipped the pointers child, sibling and return that make up a tree data structure which I described in my previous article. And a category of fields like expirationTime, childExpirationTime and mode that are specific to Scheduler.
General algorithm
React performs work in two main phases: render and commit.
During the first render phase React applies updates to components scheduled through setState or React.render and figures out what needs to be updated in the UI. If it’s the initial render, React creates a new fiber node for each element returned from the render method. In the following updates, fibers for existing React elements are re-used and updated. The result of the phase is a tree of fiber nodes marked with side-effects. The effects describe the work that needs to be done during the following commit phase. During this phase React takes a fiber tree marked with effects and applies them to instances. It goes over the list of effects and performs DOM updates and other changes visible to a user.
It’s important to understand that the work during the first render phase can be performed asynchronously. React can process one or more fiber nodes depending on the available time, then stop to stash the work done and yield to some event. It then continues from where it left off. Sometimes though, it may need to discard the work done and start from the top again. These pauses are made possible by the fact that the work performed during this phase doesn’t lead to any user-visible changes, like DOM updates. In contrast, the following commit phase is always synchronous. This is because the work performed during this stage leads to changes visible to the user, e.g. DOM updates. That’s why React needs to do them in a single pass.
Calling lifecycle methods is one type of work performed by React. Some methods are called during the render phase and others during the commitphase. Here’s the list of lifecycles called when working through the first render phase:
- [UNSAFE_]componentWillMount (deprecated)
- [UNSAFE_]componentWillReceiveProps (deprecated)
- getDerivedStateFromProps
- shouldComponentUpdate
- [UNSAFE_]componentWillUpdate (deprecated)
- render
As you can see, some legacy lifecycle methods that are executed during the render phase are marked as UNSAFE from the version 16.3. They are now called legacy lifecycles in the docs. They will be deprecated in future 16.x releases and their counterparts without the UNSAFE prefix will be removed in 17.0. You can read more about these changes and the suggested migration path here.
Are you curious about the reason for this?
Well, we’ve just learned that because the render phase doesn’t produce side-effects like DOM updates, React can process updates asynchronously to components asynchronously (potentially even doing it in multiple threads). However, the lifecycles marked with UNSAFE have often been misunderstood and subtly misused. Developers tended to put the code with side-effects inside these methods which may cause problems with the new async rendering approach. Although only their counterparts without the UNSAFE prefix will be removed, they are still likely to cause issues in the upcoming Concurrent Mode (which you can opt out of).
Here’s the list of lifecycle methods executed during the second commit phase:
- getSnapshotBeforeUpdate
- componentDidMount
- componentDidUpdate
- componentWillUnmount
Because these methods execute in the synchronous commit phase, they may contain side effects and touch the DOM.
Okay, so now we have the background to take a look at generalized algorithm used to walk the tree and perform work. Let’s dive in.
Render phase
The reconciliation algorithm always starts from the topmost HostRoot fiber node using the renderRoot function. However, React bails out of (skips) already processed fiber nodes until it finds the node with unfinished work. For example, if you call setState deep in the components tree, React will start from the top but quickly skip over the parents until it gets to the component that had its setState method called.
Main steps of the work loop
All fiber nodes are processed in the work loop. Here is the implementation of the synchronous part of the loop:
function workLoop(isYieldy) {
if (!isYieldy) {
while (nextUnitOfWork !== null) {
nextUnitOfWork = performUnitOfWork(nextUnitOfWork);
}
} else {...}
}In the code above, the nextUnitOfWork holds a reference to the fiber node from the workInProgress tree that has some work to do. As React traverses the tree of Fibers, it uses this variable to know if there’s any other fiber node with unfinished work. After the current fiber is processed, the variable will either contain the reference to the next fiber node in a tree or null. In that case React exits the work loop and is ready to commit the changes.
There are 4 main functions that are used to traverse the tree and initiate or complete the work:
To demonstrate how they are used, take a look at the following animation of traversing a fiber tree. I’ve used the simplified implementation of these functions for the demo. Each function takes a fiber node to process and as React goes down the tree you can see the currently active fiber node changes. You can clearly see on the video how the algorithm goes from one branch to the other. It first completes the work for children before moving to parents.
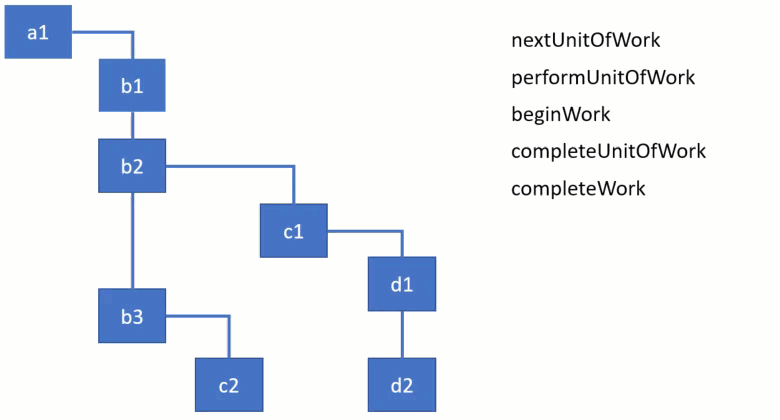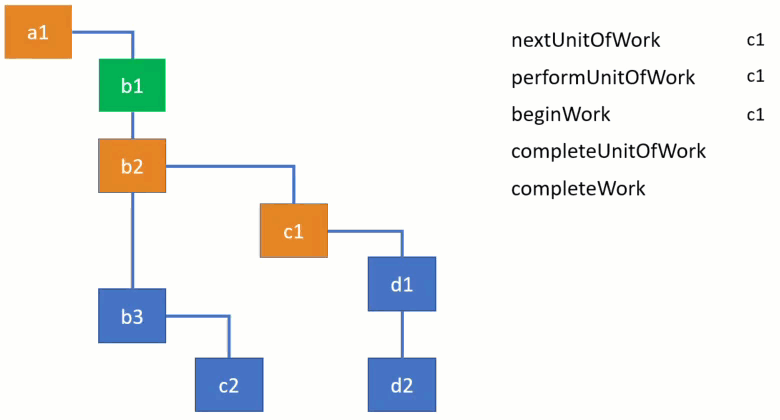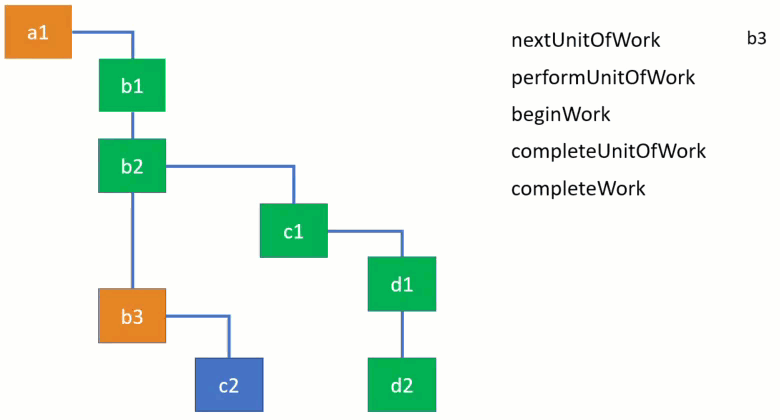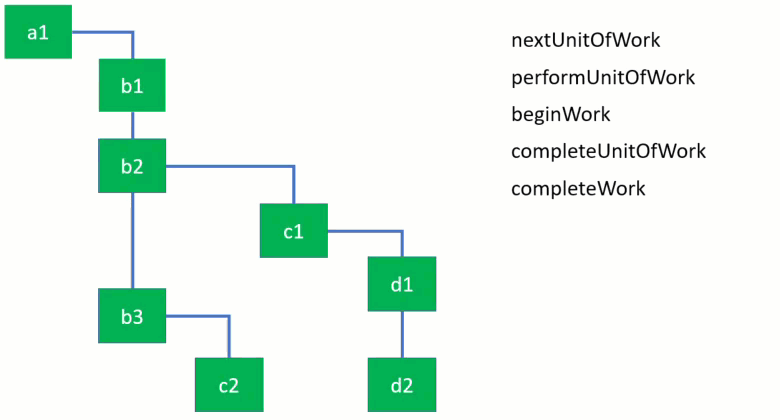
Note that straight vertical connections denote siblings, whereas bent connections denote children, e.g. b1 doesn’t have children, while b2 has one child c1.
Here’s the link to the video where you can pause the playback and inspect the current node and the state of functions. Conceptually, you can think of “begin” as “stepping into” a component, and “complete” as “stepping out” of it. You can also play with the example and the implementation here as I explain what these functions do.
Let’s start with the first two functions performUnitOfWork and beginWork:
function performUnitOfWork(workInProgress) {
let next = beginWork(workInProgress);
if (next === null) {
next = completeUnitOfWork(workInProgress);
}
return next;
}
function beginWork(workInProgress) {
console.log('work performed for ' + workInProgress.name);
return workInProgress.child;
}The function performUnitOfWork receives a fiber node from the workInProgress tree and starts the work by calling beginWork function. This is the function that will start all the activities that need to be performed for a fiber. For the purposes of this demonstration, we simply log the name of the fiber to denote that the work has been done. The function beginWork always returns a pointer to the next child to process in the loop or null.
If there’s a next child, it will be assigned to the variable nextUnitOfWork in the workLoop function. However, if there’s no child, React knows that it reached the end of the branch and so it can complete the current node. Once the node is completed, it’ll need to perform work for siblings and backtrack to the parent after that. This is done in the completeUnitOfWork function:
function completeUnitOfWork(workInProgress) {
while (true) {
let returnFiber = workInProgress.return;
let siblingFiber = workInProgress.sibling;
nextUnitOfWork = completeWork(workInProgress);
if (siblingFiber !== null) {
// If there is a sibling, return it
// to perform work for this sibling
return siblingFiber;
} else if (returnFiber !== null) {
// If there's no more work in this returnFiber,
// continue the loop to complete the parent.
workInProgress = returnFiber;
continue;
} else {
// We've reached the root.
return null;
}
}
}
function completeWork(workInProgress) {
console.log('work completed for ' + workInProgress.name);
return null;
}You can see that the gist of the function is a big while loop. React gets into this function when a workInProgress node has no children. After completing the work for the current fiber, it checks if there’s a sibling. If found, React exits the function and returns the pointer to the sibling. It will be assigned to the nextUnitOfWork variable and React will perform the work for the branch starting with this sibling. It’s important to understand that at this point React has only completed work for the preceding siblings. It hasn’t completed work for the parent node. Only once all branches starting with child nodes are completed does it complete the work for the parent node and backtracks.
As you can see from the implementation, both performUnitOfWork and completeUnitOfWork are used mostly for iteration purposes, whereas the main activities take place in the beginWork and completeWork functions. In the following articles in the series we’ll learn what happens for the ClickCountercomponent and the span node as React steps into beginWork and completeWork functions.
Commit phase
The phase begins with the function completeRoot. This is where React updates the DOM and calls pre and post mutation lifecycle methods.
When React gets to this phase, it has 2 trees and the effects list. The first tree represents the state currently rendered on the screen. Then there’s an alternate tree built during the render phase. It’s called finishedWork or workInProgress in the sources and represents the state that needs to be reflected on the screen. This alternate tree is linked similarly to the current tree through the child and sibling pointers.
And then, there’s an effects list — a subset of nodes from the finishedWorktree linked through the nextEffect pointer. Remember that the effect list is the result of running the render phase. The whole point of rendering was to determine which nodes need to be inserted, updated, or deleted, and which components need to have their lifecycle methods called. And that’s what the effect list tells us. And it’s exactly the set of nodes that’s iterated during the commit phase.
For debugging purposes, the current tree can be accessed through the currentproperty of the fiber root. The finishedWork tree can be accessed through the alternate property of the HostFiber node in the current tree.
The main function that runs during the commit phase is commitRoot. Basically, it does the following:
- Calls the
getSnapshotBeforeUpdatelifecycle method on nodes tagged with theSnapshoteffect - Calls the
componentWillUnmountlifecycle method on nodes tagged with theDeletioneffect - Performs all the DOM insertions, updates and deletions
- Sets the
finishedWorktree as current - Calls
componentDidMountlifecycle method on nodes tagged with thePlacementeffect - Calls
componentDidUpdatelifecycle method on nodes tagged with theUpdateeffect
After calling the pre-mutation method getSnapshotBeforeUpdate, React commits all the side-effects within a tree. It does it in two passes. The first pass performs all DOM (host) insertions, updates, deletions and ref unmounts. Then React assigns the finishedWork tree to the FiberRootmarking the workInProgress tree as the current tree. This is done after the first pass of the commit phase, so that the previous tree is still current during componentWillUnmount, but before the second pass, so that the finished work is current during componentDidMount/Update. In the second pass React calls all other lifecycle methods and ref callbacks. These methods are executed as a separate pass so that all placements, updates, and deletions in the entire tree have already been invoked.
Here’s the gist of the function that runs the steps described above:
function commitRoot(root, finishedWork) {
commitBeforeMutationLifecycles()
commitAllHostEffects();
root.current = finishedWork;
commitAllLifeCycles();
}Each of those sub-functions implements a loop that iterates over the list of effects and checks the type of effects. When it finds the effect pertaining to the function’s purpose, it applies it.
Pre-mutation lifecycle methods
Here is, for example, the code that iterates over an effects tree and checks if a node has the Snapshot effect:
function commitBeforeMutationLifecycles() {
while (nextEffect !== null) {
const effectTag = nextEffect.effectTag;
if (effectTag & Snapshot) {
const current = nextEffect.alternate;
commitBeforeMutationLifeCycles(current, nextEffect);
}
nextEffect = nextEffect.nextEffect;
}
}For a class component, this effect means calling the getSnapshotBeforeUpdatelifecycle method.
DOM updates
commitAllHostEffects is the function where React performs DOM updates. The function basically defines the type of operation that needs to be done for a node and executes it:
function commitAllHostEffects() {
switch (primaryEffectTag) {
case Placement: {
commitPlacement(nextEffect);
...
}
case PlacementAndUpdate: {
commitPlacement(nextEffect);
commitWork(current, nextEffect);
...
}
case Update: {
commitWork(current, nextEffect);
...
}
case Deletion: {
commitDeletion(nextEffect);
...
}
}
}It’s interesting that React calls the componentWillUnmount method as part of the deletion process in the commitDeletion function.
Post-mutation lifecycle methods
commitAllLifecycles is the function where React calls all remaining lifecycle methods componentDidUpdate and componentDidMount.
The sample code for this application is available online and you can play with it here
Learn more about AG Grid — high performance JavaScript Data Grid. We write the code to visualise data in interactive tables so you can concentrate on writing the application code. We support multiple frameworks: Angular, Vue, React so you can pick the best framework for your needs.